(5 points) In 1968, Dr. Benjamin Spock was tried in Boston on charges of conspiring to violate the Selective Service Act by encouraging young men to resist the draft for military service in Vietnam. The defense in the case challenged the method of jury selection claiming that women were underrepresented on jury panels by the process. The defense argued specifically that the judge in the Spock trial had a history of venires (panels of potential jurors) in which women were systematically underrepresented compared to the venires of six other Boston area district judges. These data can be found in case0502 in the Sleuth3 package.
Analyze the data by treating the number of women out of 30 people on a venire as a binomial response (that is, you’ll change the percent women in the datasheet to a count by multiplying by 30 and rounding) and judge as an explanatory variable.
Re-write- Defense claims women are underrepresented on jury. case0502
a. Over dispersion
Is there evidence of over dispersion in these data? Please explain (i.e., don’t just answer “yes” or “no”).
\[
log(odds) = -0.66329422A + 0.01974398B -0.23749233C -0.34830669D -0.37690731E -0.32945007F -1.08590564S
\] All the variables are dummy variables. Meaning each coefficient is also the log odds for that judge.
The multiplicative confidence intervals seem to tell the same story. Judges B through F potentially have the same odds of picking females as Judge A. However, Spock’s odds are between 21% and 54% the odds of A.
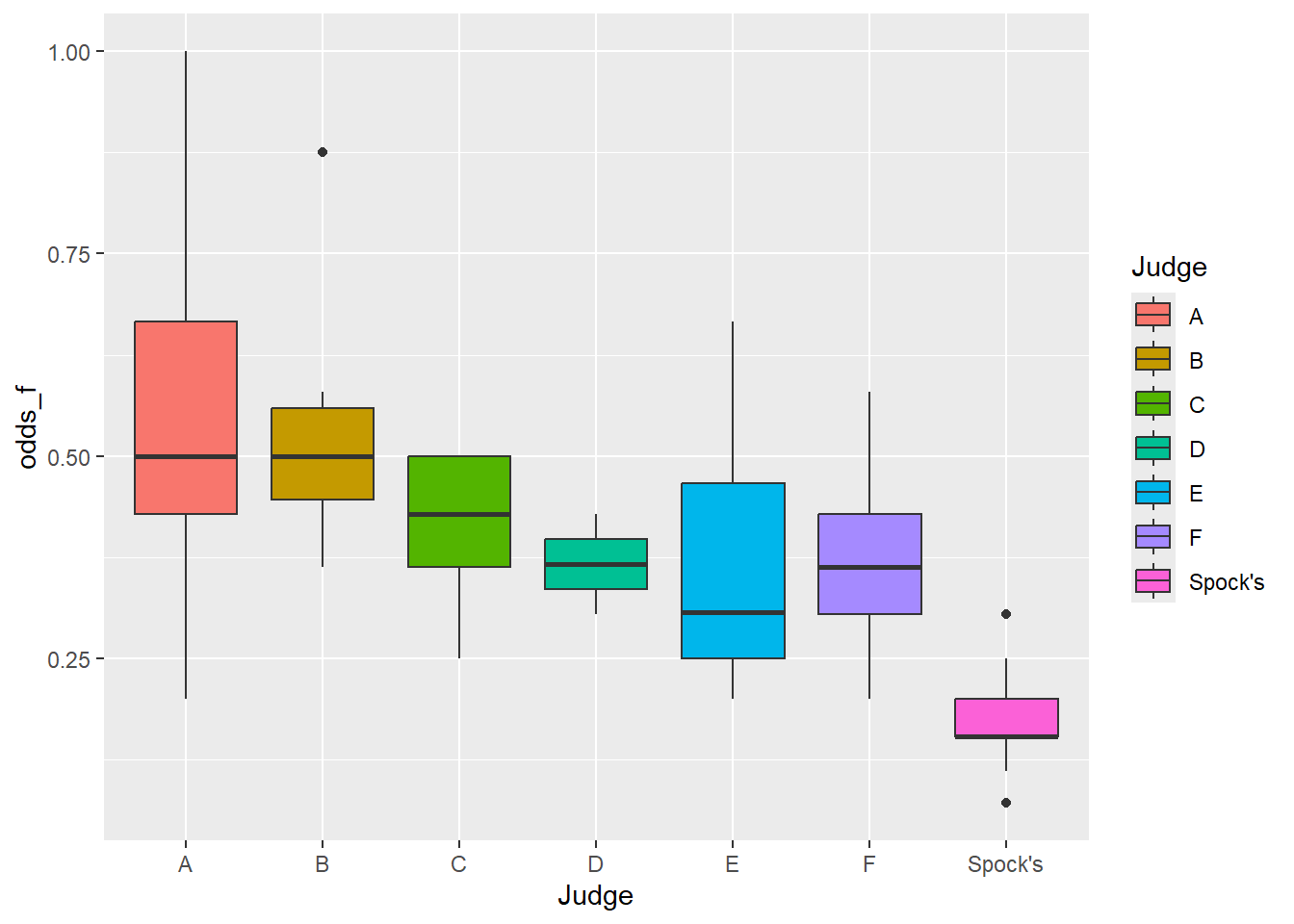
df4 <- df1 |>mutate(prop_f = female/n, odds_f = ((prop_f)/(1- prop_f)))ggplot(df4) +aes(x = Judge, y = odds_f, fill = Judge) +geom_boxplot()
Graphically, it is more obvious that there is a difference between the judges. Spock is the most obvious difference.
anova
dfanova <- df1 |>mutate(tot = n,male = tot - female,j =1) t <- dfanova |>mutate(id =row_number()) |>pivot_wider(names_from = Judge, values_from = j, id_cols =c(id, female, male, tot),values_fill =0) |>rename(S =`Spock's`, f ='F') |>relocate(S, .after ="f")mf <-glm((female/tot)~B+C+D+E+f+S, weights = tot,data = t, family ="binomial") ms <-glm((female/tot)~B+C+D+E+f, weights = tot,data = t, family ="binomial") mF <-glm((female/tot)~B+C+D+E+S, weights = tot,data = t, family ="binomial") me <-glm((female/tot)~B+C+D+f+S, weights = tot,data = t, family ="binomial") md <-glm((female/tot)~B+C+E+f+S, weights = tot,data = t, family ="binomial") mc <-glm((female/tot)~B+D+E+f+S, weights = tot,data = t, family ="binomial") mb <-glm((female/tot)~C+D+E+f+S, weights = tot,data = t, family ="binomial") mods <-c('ms', 'mF', 'me', 'md', 'mc', 'mb')for (i in1:6) {print(mods[i]) name <-get(mods[i])print(pchisq((anova(name, mf)$Deviance[2]), 1, lower.tail = F))}
The model without Spock is the only one that rejects the null hypothesis that the coefficients are equal. The full model, with Spock, is a better fit. The factor “Spock’s” is not equal to zero, Spock is different than the others.
c. Judges A-F
think about what models you could compare using drop-in-deviance tests.
Do judges A-F differ in their probabilities of selecting females to the venire? Please explain.
There may be differences between judges A through F, but the 95% confidence intervals seem to indicate that it is plausible that these judges all have roughly to same odds of choosing females. The confidence intervals contain 1 and they are multiplicative off of A. Meaning judges B through F are all choosing at roughly the same rate.
Testing the remaining judges, the all fail to reject the null hypothesis. Judges A though F are equally likely to choose females.
d. Spock v everyone.
How different are the odds of having a woman on the Spock judge’s venires from the odds of having a woman on the venires of other judges? Please explain.
think about what models you could compare using drop-in-deviance tests.
As stated in part B, the odds of being on each judges venire are : All in favor of choosing a male and against 1
A: 1.941176
B: 1.903226
C: 2.461538
D: 2.75
E: 2.829787
f: 2.69863
Spock: 5.75
Comparing the ratios of the odds of Spock choosing a female vs the other judges,
5.75/1.941176
[1] 2.962122
5.75/1.903226
[1] 3.021186
5.75/2.461538
[1] 2.335938
5.75/2.75
[1] 2.090909
5.75/2.829787
[1] 2.031955
5.75/2.69863
[1] 2.130711
5.75/5.75
[1] 1
Spock is about:
3 times more likely to choose male than A,
3 times more likely than B,
2.33 times more likely than C,
2.1 times more likely than D,
2.0 times more likely than E, and
2.1 times more likely than F.
The ANOVA in parts b and c showed that Spock is the only judge that is significantly different among this group. (Drop in Deviance test, P-value = 6.975788e-06 on 1 df).
Conceptual Questions
2. Extra-binomial variation
(2 points) Give three explanations for why you may see evidence of extra-binomial variation in a logistic regression.
Extra-binomial variation could come from variables not represented in the model, outliers, or lack of independence. Unrepresented variables add noise because we are not predicting for their effect. Outliers are noise and come from a variety of sources, sometimes they are just mistakes, but they could be natural. Lack of independence causes observations to be more alike, that makes variation estimates low.
3. Misleading results
(2 points) In lecture, we saw that when we fit a logistic model when extra binomial variation is present, we get standard errors that are ’too small’. Explain why this gives misleading results.
If the data have more variation than is estimated in the model, the standard errors will be too small and confidence intervals too narrow. Variation in a binomial is p(1-p). If the data are not truly from a binomial distribution and there is a larger spread, then that equation is wrong.
4. Distribution of insects surviving
(1 point) Consider an experiment that studies the number of insects that survive a certain dose of an insecticide, using several batches of insects of size n each. The insects may be sensitive to factors that vary among batches during the experiment but these factors (such as temperature) were unmeasured. Explain why the distribution of the number of insects per batch surviving the experiment might show over dispersion relative to a binomial(n, p) distribution.
The insects in each batch are not independent of one another, they live together. Furthermore, each batch of insects is subject to unmeasured variables that are not in the model.